 When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....
When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....
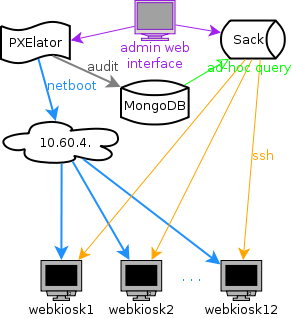
I decided to split my system into three logical parts: network booting, data store, and quick reporting. So, let's take a look at each component separately:
- PXElator
- supported protocols: bootp, dhcp, tftp, http, amt, wol, syslog
- boot kiosks using Webconverger (Debian Live based kiosk distribution)
- provides web user interface for overview of network segment for audit
- configuration is stored as files on disk, suitable for management with git or other source control management
- MongoDB
- NoSQL storage component which support ad-hoc queries, indexes and other goodies
- simple store for perl hashes from PXElator generated every time we see network packet from one of clients using one of supported protocols
- Sack
- fastest possible way to execute snippet of perl code over multiple machines
- this involves sharing information to nodes, executing code on all of them and collecting results back, all in sub 3 second mark!
- web user interface for cloud overview and graph generation using gnuplot
When I started implementing this system last summer, I decided to use CouchDB for storage layer. This wasn't really good choice, since I didn't need transactions, MVCC or replication. Hack, I even implemented forking for document stored in CouchDB to provide faster response to clients in PXElator.
Moving to much faster MongoDB I got ad-hoc queries which are usable (as in I can wait for them to finish) and if that's too slow, I can move data to Sack and query it directly from memory. As a happy side effect, making shards from MongoDB is much faster than using CouchDB bulk HTTP API, and it will allow me to feed shards directly from MongoDB to Sack nodes, without first creating shards on disk.
I'm quite happy how it all turned out. I can configure any host using small snippet of perl code in PXElator, issue ad-hoc queries on audit data on it in MongoDB or move data to Sack if I want to do data munging using perl.
As you noticed by now, I'm using live distribution for kiosks, and machines do have hard drivers in them. Idea was to use those disks as storage with something like Sheepdog. seems like perfect fit. With it in place, I will have real distributed, building size computer :-).