I have been following btrfs for quite some time. First I got kernel oopses with full disk (which have been fixed since), and then I began testing snapshots for incremental backup. Few weeks ago, I have taken a plunge and migrated by production server over to btrfs. I will try to summary first few weeks of my experience with it.
For a start, forget about using btrfs-tools which come with your distribution (Debian in my case). It's probably too old to include delete snapshot option which is really needed if you don't want to fill up your disk eventually. So, hop over to btrfs-progs-unstable and compile your own utilities.
With latest utilities at hand, I decided to make logical volume for each of my virtual machines. Before installing (or migrating) machine, create sub-volume. This is important because snapshot work on file-system or sub-volume level, and if you want to create incremental snapshots, you need to have sub-volume to snapshot.
root@prod:~# lvcreate -L 50G -n koha raid5
Logical volume "koha" created
root@prod:~# mkfs.btrfs /dev/raid5/koha
WARNING! - Btrfs v0.19-15-g8f55b76-dirty IS EXPERIMENTAL
WARNING! - see http://btrfs.wiki.kernel.org before using
fs created label (null) on /dev/raid5/koha
nodesize 4096 leafsize 4096 sectorsize 4096 size 50.00GB
Btrfs v0.19-15-g8f55b76-dirty
root@prod:~# mkdir /mnt/koha
root@prod:~# mount /dev/raid5/koha /mnt/koha
root@prod:~# btrfsctl -S rootfs /mnt/koha
operation complete
Btrfs v0.19-15-g8f55b76-dirty
Now, you are ready to install your machine in /mnt/koha/rootfs. After you have done that, you can create backup snapshots using something like this:
root@prod:~# mkdir /mnt/koha/.snap root@prod:~# btrfsctl -s /mnt/koha/.snap/2010-04-19 /mnt/koha/rootfs/ operation complete Btrfs v0.19-15-g8f55b76-dirty
Even, better, you can hop over to my sysadmin cookbook and fetch mksnap shell script which will create hourly snapshots of your machine for nice incremental backups. This is all nice and well, but after a while you will see that your disk-space increases all the time (which is expected because you are creating one snapshot every hour, collecting all changes).
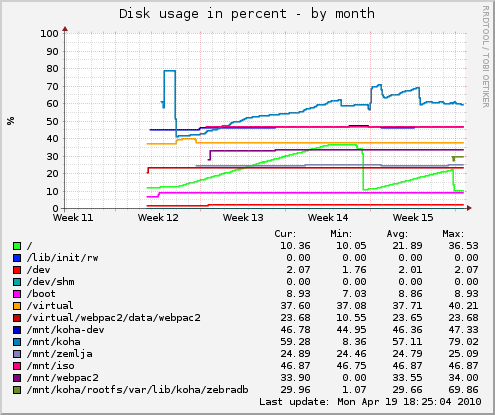
As you can see in graph above, after two weeks of such usage, I figured out what I will run out of disk space eventually, and even worse, disk fragmentation begin to take toll on performance of my server. So, I implemented small perl script to expire snapshots older than 3 days (but keep single midnight snapshot for each day). I also decided to create cron job to defragment file-system every morning.
dpavlin@prod:~$ cat /etc/cron.d/btrfs-defrag PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin # m h dom mon dow user command 15 7 * * * root btrfsctl -d /mnt/koha/rootfs/
This did help a bit, but not good enough. I have three basic services on this box: Apache web server running perl cgi scripts, MySQL database and Zebra indexer. So, in a final step of despair (before going back to ext4) I decided to move Zebra to RAID1 volume which is on two separate disks. And it did make a huge change.
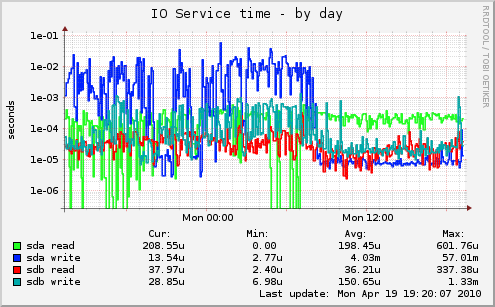
So, is btrfs ready for usage in production? That depends on your IO load. If you have to more-or-less random IO workloads (like RDBMS and full-text indexer in my example) spreading it over multiple disks will provide better performance than any choice of file-system. But, if snapshots are something useful for your use-case, give btrfs a try. Also have in mind that recovery tools for btrfs are... non-existent. So make backups (which is good idea anyway) and remember that btrfs snapshots on same disks don't count as backup.