I have been using CouchDB for some time now, mostly as audit storage for PXElator.
Audit data stores are most useful for ad-hoc queries (hum, when did I saw that host last time?), and CouchDB map/reduces took half an hour or more.
I wrote mall script couchdb2mongodb.pl to migrate my data over to MongoDB (in 26 minutes) and run first query I could write after reading MongoDB documentation about advanced queries.
It took only 30 seconds, compared to 30 minutes or more in CouchDB. I was amazed.
This was NoSQL database which I can understand and tune. MongoDB has indexes and profiler so tuning query down to three seconds was a simple matter of adding an index. All my RDBMS knowledge was reusable here, so I decided to take a look why is it so much faster than CouchDB for same data...
To be honest, MongoDB, High-Performance SQL-Free Database by Dwight Merriman, CEO of 10gen won me over to finally try MongoDB. It was technical enough to make me think about MongoDB arhitecture and benefits. It's clearly pragmatic, let's re-think horizontally scalable hash storage with ad-hoc queries model, but with funny twist about close coupling with language types all encoded in BSON format, which is very similar to Google's protocol buffers.
First, let's have a look at raw side of data on disk. At some level, it will translate to number of IO operations involving rotating platters and usage of buffer cache.
root@opr:~# du -hc /var/lib/couchdb/0.9.0/.pxelator* /var/lib/couchdb/0.9.0/pxelator.couch
655M /var/lib/couchdb/0.9.0/.pxelator_design
23M /var/lib/couchdb/0.9.0/.pxelator_temp
7.8G /var/lib/couchdb/0.9.0/pxelator.couch
8.4G total
root@opr:~# du -hc /var/lib/mongodb/pxelator.*
65M /var/lib/mongodb/pxelator.0
129M /var/lib/mongodb/pxelator.1
257M /var/lib/mongodb/pxelator.2
513M /var/lib/mongodb/pxelator.3
513M /var/lib/mongodb/pxelator.4
513M /var/lib/mongodb/pxelator.5
17M /var/lib/mongodb/pxelator.ns
2.0G total
Here is a first hint about performance: MongoDB's 2G of data (which are used as mmap memory directly, leaving flushes and caching to OS layer) are almost a perfect fit into 3G of RAM memory I have in this machine.
MongoDB has montodump utility which dumps bson for backup and it's even smaller:
root@opr:~# du -hcs dump/pxelator/*
1.1G dump/pxelator/audit.bson
4.0K dump/pxelator/system.indexes.bson
76K dump/pxelator/system.profile.bson
1.1G total
So I switched PXElator to use MongoDB as storage. I never pushed anything in production after just one day of testing it, but first query speedup from 30 min to 30 sec, and ability to cut it down to 3 sec if I added index (which took about 13 sec to create) is just something which provides me with powerful analytical tool I didn't have before.
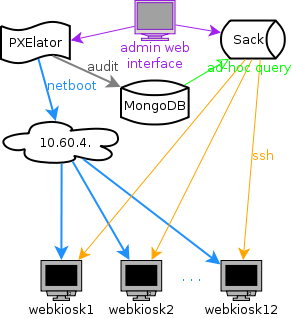 When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....
When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....