Let's assume that you want to create virtual network which spans sites (or continents :-). While we are at it, let's assume that you want to have layer 2 connectivity (because you want to run just single DHCP server for example).
At first, it seemed logical to use Virtual Distributed Ethernet for which kvm has support. However, this involves running multiple processes to support nodes on network, and it's really virtual -- you can't use familiar Linux tools (like brctl or arp) to configure it. And it's connected over ssh anyway, so why to add unnecessary complexity to setup?
Since we will use ssh to transfer traffic anyway (it easiest hole to drill over firewalls and you probably already have it for administration anyway), why do we need another layer of software in between, with new commands to learn if we already know how to make it using plain old Linux brctl?
So, let's take another look at ssh, especially option Tunnel=ethernet which provides Ethernet bridging between two tap devices. As I wrote before, ssh have point-to-point links using tun device which is great solution if you want to connect two networks on IP level using routing. However, tap devices provide access to Ethernet layer from user-space (so ssh, kvm, VDE and various others user-land programs can send and receive Ethernet packets). However, finding information on internet how to setup ssh to use tap devices is nowhere to be found and motivated me for this blog post.
Let's assume that we have two machines in following configuration:
- t61p - laptop at home behind DSL link and nat which wants to run kvm virtual machine in virtual network 172.16.10.0/24
- t42 - desktop machine at work which have network bridge called wire which has 172.16.10.0/24 network which provides network booting services
So, we need ethernet tunneling to remote client.
# install tunctl
dpavlin@t61p:/virtual/kvm$ sudo apt-get install uml-utilities
dpavlin@t61p:/virtual/kvm$ sudo tunctl -u dpavlin -t kvm0
Set 'kvm0' persistent and owned by uid 1000
dpavlin@t61p:/virtual/kvm$ kvm -net nic,macaddr=52:54:00:00:0a:3d -net tap,ifname=kvm0,script=no -boot n
This doesn't really boot our kvm from network because we didn't connect it together. Now we need to enable tunnels on
t42 and setup remote tap device
dpavlin@t42:~$ grep -v PermitTunnel /etc/ssh/sshd_config > /tmp/conf
dpavlin@t42:~$ ( grep -v PermitTunnel /etc/ssh/sshd_config ; echo PermitTunnel yes ) > /tmp/conf
dpavlin@t42:~$ diff -urw /etc/ssh/sshd_config /tmp/conf
--- /etc/ssh/sshd_config 2009-04-20 12:50:27.000000000 +0200
+++ /tmp/conf 2009-08-14 20:42:40.000000000 +0200
@@ -75,3 +75,4 @@
Subsystem sftp /usr/lib/openssh/sftp-server
UsePAM yes
+PermitTunnel yes
# install and restart ssh
dpavlin@t42:~$ sudo mv /tmp/conf /etc/ssh/sshd_config
dpavlin@t42:~$ sudo /etc/init.d/ssh restart
Restarting OpenBSD Secure Shell server: sshd.
Now we can connect two machines using ssh ethernet tunnel
dpavlin@t61p:/virtual/kvm$ sudo ssh -w 1:1 -o Tunnel=ethernet root@10.60.0.94
t42:~# ifconfig tap1
tap1 Link encap:Ethernet HWaddr fa:35:cb:9e:87:60
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
t42:~# ip link set tap1 up
t42:~# brctl addif wire tap1
t42:~# brctl show wire
bridge name bridge id STP enabled interfaces
pan0 8000.000000000000 no
wire 8000.006097472681 no eth2
eth3
tap0
tap1
tap94
t42:~# dmesg | grep tap1
[284844.064953] wire: port 5(tap1) entering learning state
t42:~# tshark -i wire
This created
tap1 devices on both machines and added one on t42 to bridge and left us with dump from
tshark on
wire bridge.
Now we need to setup virtual bridge on t61p to connect ssh tunnel and kvm tap device.
dpavlin@t61p:/virtual/kvm$ sudo ifconfig tap1
tap1 Link encap:Ethernet HWaddr 52:c5:f8:64:30:d4
BROADCAST MULTICAST MTU:1500 Metric:1
RX packets:0 errors:0 dropped:0 overruns:0 frame:0
TX packets:0 errors:0 dropped:0 overruns:0 carrier:0
collisions:0 txqueuelen:500
RX bytes:0 (0.0 B) TX bytes:0 (0.0 B)
dpavlin@t61p:/virtual/kvm$ sudo brctl addbr virtual
dpavlin@t61p:/virtual/kvm$ sudo brctl addif virtual kvm0
dpavlin@t61p:/virtual/kvm$ sudo brctl addif virtual tap1
dpavlin@t61p:/virtual/kvm$ sudo brctl show
bridge name bridge id STP enabled interfaces
pan0 8000.000000000000 no
virtual 8000.4e1537af6cdc no kvm0
tap1
dpavlin@t61p:/virtual/kvm$ sudo ip link set kvm0 up
dpavlin@t61p:/virtual/kvm$ sudo ip link set tap1 up
dpavlin@t61p:/virtual/kvm$ sudo ip link set virtual up
dpavlin@t61p:/virtual/kvm$ dmesg | grep virtual
[31141.669760] virtual: port 1(kvm0) entering learning state
[31152.288025] virtual: no IPv6 routers present
[31156.668088] virtual: port 1(kvm0) entering forwarding state
[31211.699928] virtual: port 2(tap1) entering learning state
[31226.696070] virtual: port 2(tap1) entering forwarding state
dpavlin@t61p:/virtual/kvm$ kvm -net nic,macaddr=52:54:00:00:0a:3d -net tap,ifname=kvm0,script=no -boot n
This will boot our kvm using ethernet bridge from remote server using nothing more than
brctl and
ssh !
If you wanted even more lightweight solution to same problem, you might look into EtherPuppet.
On related note, if your kvm Windows XP machines stopped working with upgrade to Debian kernel 2.6.30-1-686, just upgrade to 2.6.30-1-686-bigmem (even if you don't have more memory) and everything will be o.k.
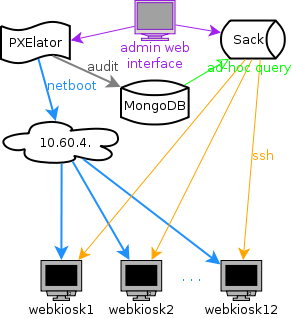 When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....
When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....