I have spent few last weeks with my head down, adding persistence and changes tracking to Mojo Facets, turning it into much more interesting alternative to web-based data stores like DabbleDB. Idea was simple: I had all data in memory, I should be able to edit it, right?
Well, as it always turns out, if was about three weeks of development, but it moved Mojo Facets into much more interesting use case of making small tweaks to your input data.
Problem is how to keep those changes? Mojo Facets is never master provider for data so saving some kind of audit log which can be applied back on master data is of paramount importance. After all, if you edit that data, you might want to apply those changes back when you re-generate source file or pull new version from some other system.
First idea was to add simple audit log which records all requests in Mojo. I decided to call requests with parameters actions and store them on disk under /tmp. All I had to add was re-submit form in browser and a bit of interface around it. Same form with all parameters can turn Mojo Facets into peer-to-peer application: I just added checkbox which can change destination URL in action to another Mojo Facets installation and I got nice replication of actions to another instance.
But, all was not well. Editing data in browser generates update to specific entry in your dataset, so I decided also to record changes which include old and new field value, and all unique keys for this dataset.
This seems like such a small statement, but getting it up to point where you can load some data, edit it in browser and than apply that changes back on original data (after reboot) or on different dataset with same unique field.
Even better, it should be possible to apply changes log to master data. I prefer to think of it as a replication log to another system.
To integrate better with other systems, filters got export (and import) option which dumps them in simple, one line per entry text file which is accessible over http. It's perfect format it you want to quickly xargs that data into another script, for example to generate more source data with something as simple as:
cat /srv/mojo_facets/public/export/isi-cro2.js/filter.autor.119 | \
xargs -i ./bin/isi-download-results.pl 'CA={}'
Speaking of more dataset sources, I also added parsing on html tables, which should allow users at some point to just drop multiple tables from results page into single directory and load them as dataset. Your telebanking doesn't have export you need? No problem! Just save all pages to disk and you are ready to do.
Right now, table parsing needs a bit of heuristics to be really useful. It searches for table on page with correct number of columns, and has support for extracting of header or repeating first row (normal <td>) for column names.
All that would be unusable without profiling to turn it really snappy. This is first time I used Google Chrome for serious development, and while I still dislike it's inspector (firebug's dom inspector is much nicer to me), Speed Tracer extension was very useful for front-end part including network throuput and html/javascript overhead. On server side, I used Devel::NYTProf, and I will talk about it at Slobodni Fastival 4 in Čakovec, so see you there...
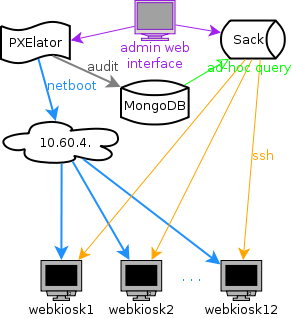 When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....
When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....