As you all know by now, last week we had another DORS/CLUC conference. This time I had two talks and one workshop.
Sysadmin cookbook
I never proparly introduced this project here, but if you want to know more about my convention based documentation examine the presentation of hop over to http://sysadmin-cookbook.rot13.org/ and take a look at generated documentation.
Basic idea is to document changes in easy to write files on file system (preserving symlinks to files on system which allows you to quickly see if cookbook is deployed or not and diff between template and deployed configuration). I know that my cookbook is mix of various things I did in last three years, but I do find it useful, so hopefully it might be useful to you also.

Kindle - so much more than ebook reader
This was longer talk about my one year experience with Kindle. I must say that I'm still very happy user of Kindle, but in this talk, I tried to cover Kindle Developer's Corner at mobileread forum as well as other related projects:- Free Libre command-line tools for Kindle development
- A PDF (plus DJVU, ePub, TXT, CHM, FB2, HTML...) viewer made for e-ink framebuffer devices, using muPDF, djvulibre, crengine mobileread forum thread
- A VNC viewer for ebook readers which allows you to use Kindle as second screen mobileread forum thread

Web scale monitoring
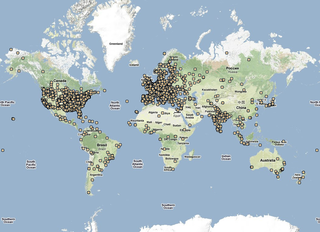
This was a workshop which doesn't have much with web (it's about monitoring ADSL CPE devices and provider equipment in-between), but it shows (I hope) nice way to integrate several project to provide nice scalable monitoring infrastructure. It's composed of:
- Gearman message queue together with Gearman::Driver provide on-demand scaling of workers
- redis saves all data from external systems (LDAP, CRM) and all results from statistics collection nicely providing data for web interface
- PostgreSQL stores all collected data, using hstore to provide unstructured key value store for different data from different devices while still allowing us to use SQL to query data (and export it to data warehouse)
- Mojolicious provides web interface which uses data from redis and provides JSONP REST interface for Angular.js