Last year, I had good fortune to get acquiented with great work which Open Library does. It's part of Internet Archive which itself is a library. So, libraries are not (yet) dead it seems. Brewster Kahle's Long Now Talk explains it much better than I can do, so take 90 minutes to listen to it.
Most interesting part of Open Library (IMHO) is Internet Archive BookReader which is JavaScript application which allows users to browse scanned books on-line. For quite some time, I wanted to install something similar to provide web access to our collection of scanned documents. I have found instructions for serving IA like books from own cluster, but I didn't have a cluster, and converting all documents to IA book format seemed like an overhead which I would like to avoid.
Instead, I decided to write image server for JavaScript front-end using plack. I mean, it's basically a directory with images, right? Oh, how wrong can I be? :-)
It turs out that we have pictures in multiple formats (so sorting them required removing common prefix and using number only to get correct order), and most of are scanned images in pdf documents. Here are all types of documents which can be automatically collected into book for on-line browsing:
images of scanned pages
multi-file pdf file with single image per page
single pdf file with one image for each page
single pdf file with more than one (usually 4) horizontal bitmap strips for each page
normal pdf documents which contain text and needs rendering to bitmap
A week ago, I stumbled by accident on <angular/> via Angular: A Radically Different Way of Building AJAX Apps. I was hooked. Making html ultimate template language by annotating it with few attributes and having two-way data-binding between input forms and objects which can be stored directly in the cloud make a lot of sense for me.
First a bit of history. Back in 2003 I wrote a small tool called wopi (Web Online Poll Interface) to generate on-line polls easily. It was basically html template with few magic fields which would be parsed by perl script to produce php code and database schema for deployment.
I was aware that this approach simply doesn't make sense any more, since browsers can do much more than in 2003, and we have flexible storage systems like CouchDB which doesn't require us having pre-defined data schema.
First I decided to try out hosted service at getangular.com to see if I can create working application in an afternoon. And I could.
Then I tried examples which worked on API at getangular.com against angular.js checkout on github, and I was at first surprised that things like ng-entity didn't exists in checkout. However, since storage API is part of hosting offer, that made sense. I will have to implement my own REST storage anyway, and REST API for angular hosting service is documented.
Now, I needed to write some kind of REST storage against which I can test my angular controllers which I was writing.
angular-mojolicious is in-memory data store using documented REST API based on mojolicious lightweight perl web framework. In current stage, it provides ability to replicate data from shared storage and provides support for $resource call in angular.
Application which I was writing was simple conference submission app. Basically, one work per submission, but with possibility to group a bunch of works in symposium (single topic which have additional data).
I decided to duplicate symposium work inside each work to make this simple (and store number of work within symposium) and simply copy symposium data from first work to second work within same symposium.
However, I wanted to display all works within symposium and my REST back-end doesn't have any query capability yet (aside from returning all objects). At first, I just added additional javascript object symposium which stores all works within singe symposium in order, mostly so I can display list of works which are part of same symposium.
And again, implementing something visible on screen (list of works within symposium) I created something I can simply wrap into another $resource and store it on server, creating a data view which I needed.
All this duplication of data still seems a bit strange to my relational brain, and pure size of POST request to store symposium data with all works included could be prohibitively expensiveness for hundred of works. However, all data needed for symposium is stored within Work documents, so I could just write server side code which would update Symposium objects directly when Works are updated (something like stored procedures in relational lingo).
In the process, I also learned to pull upstream angular code often, because developers are very active, and any bug you might hitting now might already be fixed in upstream git. I learned it hard way, trying to figure out why my app isn't working while fix was already at angular's github repository. Kudos to fast release cycle.
Any sufficiently advanced technology is indistinguishable from magic.
[Artur C. Clarke]
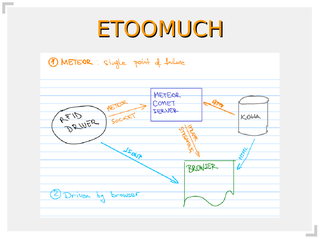
As you know by now, I'm working pure free software implementation of RFID support for our library. This time, I decided to tackle problem of printing RFID cards using EVOLIS Dualys printer.
This is experimental support for EVOLIS Dualys 3 printer with black ribbon (K)
to provide pixel-exact driver with support for two-side printing.
but I haven't been able to make it print on both sides of cards,
partly because using duplex option in cups seems to segfault GhostScript
and/or rastertoevolis cups filter depending on combination of duplex
options.
I also needed pixel perfect transfer to printer, and cups
bitmap format is always in color, leaving final pixel modifications down
to cups filter which always produced differences between file sent to
printer and perfect black and white rendition of it.
SCRIPTS
Current toolset consists of following scripts:
inkscape-render.pl card/template.svg 201008159999 login Name Surname
Generate pdf files from Inkscape SVG template in card/ using
print-front and print-back object IDs. Layers doesn't work
since we can't toggle visilbity easily. To print more than one
object gruop them and change ID of group.
After pdf files are created, GhostScript is used to rasterize them
into pbm (monochrome) bitmaps.
Provides driver which generates printer command stream to print
two-sided card from pbm files.
evolis-simulator.pl evolis
Simulator for EVOLIS printer commands which is useful for development.
It creates one pbm file per page printed.
scripts/evolis-command.pl
Command-line interface to send commands to printer and receive responses.
Supports readline for editing and history.
Requires local parallel port connection, probably to USB parallel device.
EXAMPLE
Following is simple walk-through from svg image in Inkscape to
evolis command stream which can be executed in top-level directory
of this distribution:
But, two years of development and trying out different approaches produced not-quite-production-quality code. So, I began rewrite called Biblio::RFID. It splits RFID reader support from HTTP and JSONP servers and couples this with documentation and tests. I have production use for it this summer, involving programming of RFID cards as they are printed out, so expect it to change during next few weeks. After that I will push it to CPAN, but I would love to get feedback and comments before that.
I have spent few last weeks with my head down, adding persistence and changes tracking to Mojo Facets, turning it into much more interesting alternative to web-based data stores like DabbleDB. Idea was simple: I had all data in memory, I should be able to edit it, right?
Well, as it always turns out, if was about three weeks of development, but it moved Mojo Facets into much more interesting use case of making small tweaks to your input data.
Problem is how to keep those changes? Mojo Facets is never master provider for data so saving some kind of audit log which can be applied back on master data is of paramount importance. After all, if you edit that data, you might want to apply those changes back when you re-generate source file or pull new version from some other system.
First idea was to add simple audit log which records all requests in Mojo. I decided to call requests with parameters actions and store them on disk under /tmp. All I had to add was re-submit form in browser and a bit of interface around it. Same form with all parameters can turn Mojo Facets into peer-to-peer application: I just added checkbox which can change destination URL in action to another Mojo Facets installation and I got nice replication of actions to another instance.
But, all was not well. Editing data in browser generates update to specific entry in your dataset, so I decided also to record changes which include old and new field value, and all unique keys for this dataset.
This seems like such a small statement, but getting it up to point where you can load some data, edit it in browser and than apply that changes back on original data (after reboot) or on different dataset with same unique field.
Even better, it should be possible to apply changes log to master data. I prefer to think of it as a replication log to another system.
To integrate better with other systems, filters got export (and import) option which dumps them in simple, one line per entry text file which is accessible over http. It's perfect format it you want to quickly xargs that data into another script, for example to generate more source data with something as simple as:
Speaking of more dataset sources, I also added parsing on html tables, which should allow users at some point to just drop multiple tables from results page into single directory and load them as dataset. Your telebanking doesn't have export you need? No problem! Just save all pages to disk and you are ready to do.
Right now, table parsing needs a bit of heuristics to be really useful. It searches for table on page with correct number of columns, and has support for extracting of header or repeating first row (normal <td>) for column names.
All that would be unusable without profiling to turn it really snappy. This is first time I used Google Chrome for serious development, and while I still dislike it's inspector (firebug's dom inspector is much nicer to me), Speed Tracer extension was very useful for front-end part including network throuput and html/javascript overhead. On server side, I used Devel::NYTProf, and I will talk about it at Slobodni Fastival 4 in Čakovec, so see you there...
I am huge fan of Exhibit faceted browsing of data. However, Exhibit is implemented in JavaScript within your browser and that makes it unusable for larger amounts of data (more than 300 or so). In my case, 3800 elements is unusably slow even in latest Chrome or Firefox.
Something had to be done. If JavaScript inside browser isn't up to the task, you might wonder what would happen if you moved processing back to server side, and use browser just for task which they are good at: displaying generated HTML pages.
Although it seems strange to promote server-side solutions in 2010, this approach still makes sense. For just 40Mb of memory usage server side (including Mojo and dataset) you can get fast and usable facet browsing.
video annotation interface based on mplayer with slide overview
web interface using HTML5 <video> tag and some JavaScript
I have collected some of presentations at http://html5tv.rot13.org/, so hop over there and have a look. If you have more interesting presentations, you can easily fork HTML5TV at github, annotate presentation and submit it for inclusion (or make your own archive if you prefer that). Have fun and let me know what you think about it.
Main design goal is to have interactive environment to query perl hashes which are bigger than memory on single machine.
Implementation uses TCP sockets (over ssh if needed) between perl processes. This allows horizontal scalability both on multi-core machines as well as across the network to additional machines.
Reading data into hash is done using any perl module which returns perl hash and supports offset and limit to select just subset of data (this is required to create disjunctive shards). Parsing of source file is done on master node (called lorry) which then splits it to shards and send data to sack nodes.
Views are small perl snippets which are called for each record on each shard with $rec. Views create data in $out hash which is automatically merged on master node.
You can influence default shard merge by adding + (plus sign) in name of your key to indicate that key => value pairs below should have values summed when combining shards on master node.
If view operation generate huge amount of long field names, you might run out of memory on master node when merging results. Solution is to add # to name of key which will turn key names into integers which use less memory.
So, how does it look? Below is small video showing 121887 records spread over 18 cores on 9 machines running first few short views, and than largest one on this dataset.
Source code for Sack is available in my subversion and this is currently second iteration which brings much simpler network protocol (based only on perl objects serialized directly to socket using Storable) and better support for starting and controlling cluster (which used to be shell script).
As you might know by now, I have been really struck by simplicity of CouchDB at last year's OSCON. From then, we got couchapp which is great idea of hosting CouchDB views on file-system for easy maintenance.
So good in fact, that I re-wrote couchapp in perl called design-couch.pl. I needed to deviate a bit from original design (one _design document per application) because PXElator data which I store in CouchDB is... data...
I have been introduced to Relational databases back at university and since then I have been using PostgreSQL for all my database needs. But, this time, I have dumps from commands, SOAP interfaces, syslog messages and arbitrary audit events generated all over the code. I didn't want to think about structure up-front, and View Cookbook for SQL Jockeys convinced me I don't have to, but I decided to make few simple rules to get me started:
Create URLs using humanly readable timestamps (yyyy-mm-dd.HH:MM:SS.package.ident) which allows easy parsing in JavaScript (if needed), and ensures that all entries are sorted by time-stamp
Augment each document with single new key package (perl keyword on top of each module). It will have sub-keys time decimal time-stamp, name of package, caller sub which called CouchDB::audit and line from which it's called
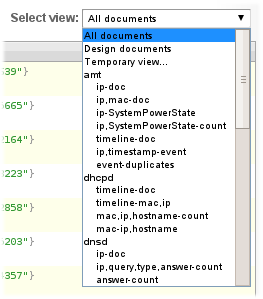
Single _design document for output from one package (which is directory on file-system) just because it easy browsable in Futon.
So, are those rules enough to forget about relational algebra and relax on the couch? Let's take a look at _design/amt/ip,SystemPowerState-count. I applied here almost SQL-ish naming convention - column names, separated by commas then dash - and output column(s).
function (k,values,rereduce) {
if (rereduce) {
var total_sum = 0;
var total_length = 0;
for (var i = 0; i < values.length; i++) {
total_sum += values[i][0];
total_length += values[i][1];
}
return [total_sum, total_length];
} else {
return [sum(values), values.length];
}
}
Since we are called incrementally, we can't average averages. We need to collect total sum and number of elements and perform final computation on client:
Key
Value
"193.198.212.4"
[779.0038585662847, 9]
"193.198.212.228"
[902.6305675506585, 10]
"192.168.1.61"
[906.698703765869, 11]
"192.168.1.34"
[995.9852695465088, 11]
"192.168.1.3"
[316.55669212341303, 6]
"192.168.1.20"
[506.162643432617, 8]
"192.168.1.2"
[473.91605377197277, 11]
"192.168.1.13"
[649.2500305175784, 11]
"172.16.10.10"
[49.9579906463623, 1]
"172.16.10.1"
[250.78511238098127, 15]
"127.0.0.1"
[62.57653236389161, 16]
"10.60.0.94"
[81.6218852996826, 2]
"10.60.0.93"
[186.49005889892578, 6]
"10.60.0.92"
[386.7535591125485, 5]
"10.60.0.91"
[1070.863485336304, 9]
"10.60.0.90"
[428.4689426422117, 10]
If you manage to wrap your head around this, you are ready to dive into CouchDB.
I have been thinking about poor state of Linux video for quite some time (bear in mind that I do have real-life experience with U-matic type equipment) but it seems that things are moving in right direction. Here is a quick comilation of useful links from this presentation:
Pad.ma in interesting project with source available which enables usable cut-edit video over the web if you are using browser with <video> tag support like Firefox 3.5.
This is very cool! Only problem for me right now is that server side is written in python with which I haven't have good experience (it's just my bias). But, than again Pad.ma JavaScript API seems easy enough to roll out own server implementation if I find time to play with it.