Internet is not a single network. Some parts of it are hidden behind firewalls, some services allows access only from specific range of IP addresses. To solve that, we are using proxy servers, but what do you do when you want to allow your users easy access to resources which are not directly accessible?
For a long time, I was fan of CGIProxy. Single CGI script which allows you to access all web resources which are visible from machine on which CGIProxy is installed. However, modern web pages have many, many elements, and soon enough overhead of CGI execution for each element proved to be too much for our users patience. It was slow...
I decided to take a look at mod_perl2 as solution since it provides long-living perl interpreter inside Apache 2 server. I was on the right track: Apache2::ModProxyPerlHtml provides easy to configure html rewriter using Apache 2 and mod_perl2. I tested it and immediately saw speedup comparing to previous CGIProxy based solution.
But, this was only half of problem. I also needed to solve user authorization somehow. With old system, we had LDAP server as login method, but this time, I needed to somehow check user passwords in Koha database which are base64 encoded md5 hash of password. Base64 is somewhat unfortunate choice because MySQL doesn't have built-in base64 encoding. If it did, I could just use Apache::AuthDBI, craft SQL queries and I would be ready to go.
First idea was to write Apache2 auth module which would connect to Koha directly. That would work, but it would also require secure connection between proxy and Koha (we are transfering passwords) and proxy would need to have credentials to access Koha database. None of that seemed very clean or secure, so I decided to split it into two parts:
- Apache auth module which requests credential verification from Koha server over https
- CGI script on Koha which verifies user and return status
With this approach, passwords are never traveling across network (and even md5 hash of password is transfered over ssl) and proxy server doesn't have to have any Koha specific configuration.
Here is small Apache authorization module which will transfer userid and base64 encoded password hash to cgi script on Koha server over https:
package Apache2::AuthKoha;
use strict;
use warnings;
use Apache2::Access ();
use Apache2::RequestUtil ();
use Apache2::Const -compile => qw(OK DECLINED HTTP_UNAUTHORIZED);
use Digest::MD5 qw/md5_base64/;
use LWP::Simple qw/get/;
sub handler {
my $r = shift;
my ($status, $password) = $r->get_basic_auth_pw;
return $status unless $status == Apache2::Const::OK;
return Apache2::Const::OK if get(
'https://koha.example.com/koha-auth?userid=' . $r->user .
';password=' . md5_base64($password)
);
$r->note_basic_auth_failure;
#return Apache2::Const::DECLINED; # allow other authentification
return Apache2::Const::HTTP_UNAUTHORIZED;
}
1;
And this is small CGI script on Koha server's side which checks userid and password hash and returns appropriate status:
#!/usr/bin/perl
# ScriptAlias /koha-auth /srv/koha-auth/auth.cgi
use warnings;
use strict;
use CGI;
use DBI;
our $dsn = 'DBI:mysql:dbname=koha';
our $user = 'koha-database-user';
our $passwd = 'koha-database-password';
my $q = CGI->new;
my $status = 200;
sub out {
my ($status,$text) = @_;
print $q->header( -status => $status ), "$text\r\n";
exit;
}
out( 500, "NO PARAMS" ) unless $q->param;
my $dbh = DBI->connect($dsn, $user,$passwd, { RaiseError => 1, AutoCommit => 0 }) || die $DBI::errstr;
my $sth = $dbh->prepare(q{
select 1 from borrowers where userid = ? and password = ?
});
my ( $userid, $password ) = ( $q->param('userid'), $q->param('password') );
$password =~ s{ }{+}g;
$sth->execute( $userid, $password );
if ( $sth->rows == 1 ) {
out( 200, "OK" );
} else {
out( 404, "ERROR" );
}
To complete this setup, we also have to define virtual host on proxy server which will tie together our components:
<VirtualHost *:443>
SSLEngine on
SSLCertificateFile /etc/apache2/proxy.example.org.pem
SSLCertificateKeyFile /etc/apache2/proxy.example.org.pem
ServerName proxy.example.org
ProxyRequests Off
ProxyPreserveHost Off
PerlInputFilterHandler Apache2::ModProxyPerlHtml
PerlOutputFilterHandler Apache2::ModProxyPerlHtml
SetHandler perl-script
PerlSetVar ProxyHTMLVerbose "On"
<Proxy *>
Order deny,allow
Allow from all
</Proxy>
PerlAuthenHandler Apache2::AuthenDBMCache Apache2::AuthKoha
PerlSetVar AuthenDBMCache_File /tmp/auth-cache
PerlSetVar AuthenDBMCache_TTL 3600
PerlSetVar AuthenDBMCache_Debug On
ProxyPass /secure/ http://secure.example.com/
<Location /secure/>
ProxyPassReverse /
PerlAddVar ProxyHTMLURLMap "/ /secure/"
PerlAddVar ProxyHTMLURLMap "http://secure.example.com /secure"
AuthName Proxy
AuthType Basic
require valid-user
</Location>
</VirtualHost>
This will enable you to access http://proxy.example.org/secure/ and get access to http://secure.example.com/
You will also notice that I'm using Apache2::AuthenDBMCache to prevent proxy from checking user credential for every page element (which would be slow). At first, this setup didn't work well. I would get No access to /tmp/auth-cache at -e line 0 because client browser was opening multiple connection at same time and perl's dbmopen didn't like that. Fortunatly, it was easy to fix, so I just added use DB_File; in Apache2::AuthenDBMCache which forced dbmopen to use Berkeley DB (which allows multiple readers) instead of default GDBM.
Once again, perl proved to be duct tape of Internet. With a few lines of code and some configuration you can make wonderful things. So, why don't you? :-)
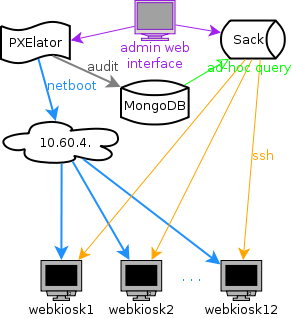 When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....
When you are working as system architect or systems librarian, your job is to design systems. My initial idea was to create small Google out of 12 machines which are dedicated to be web kiosks. I decided to strictly follow loosely coupled principle, mostly to provide horizontal scaling for my data processing needs. I wanted to be able to add machine or two if my query is too slow... This easily translates into "now long will I have to wait for my page to generate results"....